Come usare i dati e le curve sul coronavirus

In questi giorni ho letto il libro di Michele Mezza Il contagio dell’algoritmo, un non-instant book sulla pandemia – è uscito lo scorso ottobre, dopo la fine della prima ondata Covid ma prima della seconda e terza – che fa un paragone tra la situazione mondiale per il controllo della pandemia e la situazione mondiale per il controllo dei dati. Per dare un’idea, usa termini come “i calcolanti” e “il regime computazionale”. Se ho compreso bene, la sua tesi è che abbiamo avuto un passaggio alla rovescia: non sono le dinamiche della rete a scimmiottare quelle della vita reale, ma queste ultime stanno mostrando dinamiche tipicamente di rete: ne parlo comunque un po’ più diffusamente sul mio blog.
Ci sono parti del libro, come quella in cui racconta come la pandemia abbia inferto un colpo probabilmente mortale al mestiere del giornalista che già negli ultimi vent’anni era inesorabilmente scivolato verso quello di aggregatore, che mi vedono d’accordo; ci sono altre parti, come quella sui comportamenti dei vari partiti politici nei confronti della pandemia oppure sull’accaparramento dei dati da parte dei grandi Over The Top che hanno messo da parte gli stati nazionali, su cui potremmo proficuamente discutere. Per i curiosi, ho raccolto alcuni spunti che mi sono venuti in mente leggendolo. Ma qui parlo di matematica, e quindi mi limito a trattare un punto su cui non sono invece per nulla d’accordo sulla sua diatriba contro la disumanizzazione e algoritmizzazione della medicina.
Per spiegarmi meglio, riporto un paio di passi del libro. A pagina 34, parlando dei dati sull’andamento dei contagi che arrivano puntualmente tutti i pomeriggi, Mezza scrive:
«I dati sul contagio non possono mai essere contabilizzati per quello che immediatamente rappresentano, ma sempre decifrati per il trend dinamico a cui possono preludere.»
mentre nella pagina successiva fa sua la citazione di un altro autore noto per le sue posizioni fuori dal coro, James Lovelock (che forse ricorderete per il suo libro Gaia del 1979 ):
«Lovelock [in Novacene, Bollati Boringhieri 2020] ci soccorre anche per capire come considerare allora la cascata di valutazioni numeriche che ancora cercano di ingabbiare le metamorfosi virali in una semplice tabella: ‘ciò che hanno fatto gli ingegneri è stato un elegante inganno: è sembrato che spiegassero il funzionamento del sistema, ma in realtà si sono limitati a descriverlo nei dettagli’.»
A onor del vero, il ragionamento di Mezza riguardo ai dati mi pare piuttosto ambivalente. Poche righe sotto scrive infatti:
Su questo aspetto delle certezze che chiediamo alla scienza, mi pare esauriente e autorevole la spiegazione che proprio il professor Andrea Crisanti presenta nel suo contributo a questo libro, quando parla della relatività e contestualità dei dati, che in ogni caso rimangono gli indicatori più efficaci per misurare la potenza espansiva del virus.
Questa frase mi pare un po’ cerchiobottista, visto che a quanto pare ammette che i dati in fin dei conti servono. Ad ogni modo mi preme parlare di alcune cose che probabilmente per chi fa matematica sono naturali ma non vengono mai spiegate. Cominciando dalla citazione di Lovelock, ho forti dubbi sul fatto che gli “ingegneri” vogliano spiegare qualcosa. Loro devono appunto far funzionare le cose, non sono interessati a spiegarle. Chi cerca di spiegare di solito sono i fisici, come Paolo Giordano anch’egli molto citato in questo libro. I matematici in generale cercano piuttosto di tirare fuori dei modelli; ma dopo essere stati scottati dalle geometrie non euclidee prima e soprattutto dai teoremi di incompletezza di Gödel poi, tendono a non dare troppe patenti di verità a quello che trovano. Insomma, per la maggior parte dei matematici non importa poi tanto spiegare come funziona un sistema, quanto appunto riuscire a descriverlo in maniera utile, evitando le approssimazioni dei cavalli sferici della vecchia barzelletta.
Un esempio di un’altra comune fallacia che ho trovato nel libro si può leggere a pagina 72, quando Mezza scrive che c’erano state molte richieste a Google Trends riguardo a “sintomi influenzali anomali e perdita d’olfatto” e “nessuno pretese di accedere a quelle black box”. Qui il problema non è tanto che Google Trends sia comunque pubblico e quindi si sarebbe potuto fare comunque la ricerca: è molto probabile che a Mountain View abbiano molti più dati di quelli resi pubblici, quindi la richiesta di accesso per cause eccezionali è fondata. Il problema è che questo è il classico tipo di ricerca che si può fare a posteriori. A chi poteva venire in mente di cercare “anosmia” prima di sapere che era un sintomo del Covid? Nelle due figure qui sotto potete vedere lo storico delle ricerche per la parola in Italia su Google Trends e Wikipedia Pageview. È facile notare come il numero di ricerche del termine cominci a superare seriamente la soglia di “rumore di fondo” proprio quando è partito il primo lockdown; anche senza pensare che non ci sia un rapporto di causa-effetto e si cercasse la parola perché i media ne parlavano non abbiamo comunque una predizione quanto un accadimento in parallelo. Per quanto riguarda i sintomi influenzali, poi, vedere un picco di domande su sintomi influenzali strani può far pensare a un picco dell’influenza “standard”.
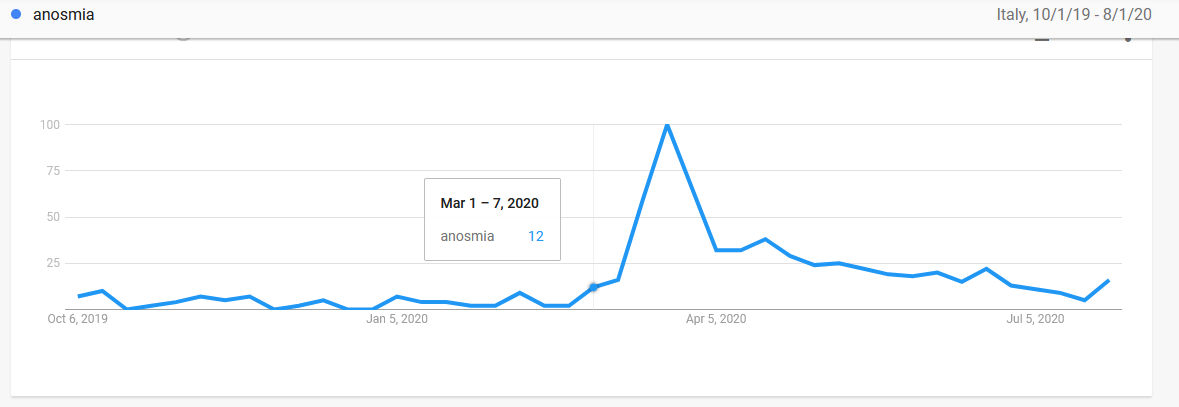
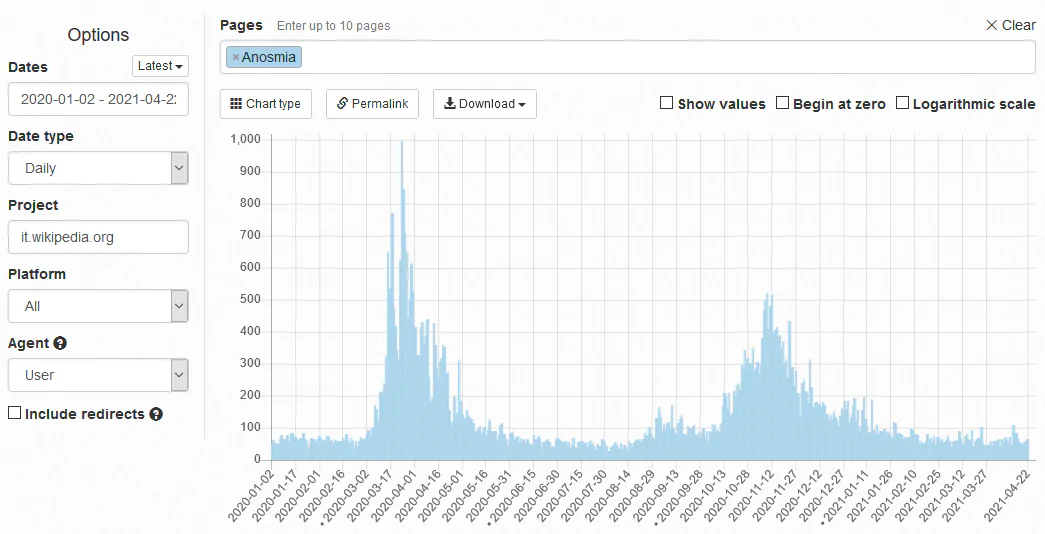
Qualcuno potrebbe giustamente dire “Sì, ma chi diavolo conosceva la parola anosmia prima di questa pandemia? Questa ricerca non prova nulla”. Indubbiamente la prima affermazione è vera; almeno per quanto mi riguarda, non avevo mai sentito quel termine prima dell’esplodere della pandemia, e sono pronto a scommettere che lo stesso vale per la maggior parte di voi. È per questo che alla ricerca su Google Trends – che può essere fatta con le chiavi più disparate – ho aggiunto quella su Wikipedia. L’idea di base è che chi cerca informazioni e trova un nome tecnico va a vedere cosa dice Wikipedia su di esso; e direi che c’è una correlazione piuttosto stretta. A parte questo, torniamo al punto iniziale. Come facevamo a sapere quali erano le chiavi di ricerca in grado di “prevedere” il Covid?
Avevamo visto qualche anno fa il flop di Google Flu Trends: sembrava che i “calcolanti” di Google avessero trovato le stringhe di ricerca per anticipare le informazioni che arrivavano tramite i medici sui picchi dell’influenza stagionale, ma dopo i primi risultati incoraggianti l’anno successivo le previsioni crollarono. Insomma, è facile trovare le domande da fare, ma solo dopo che si sanno già le risposte e quindi delle domande non ce ne facciamo più molto. Bisogna dire che Douglas Adams era stato preveggente anche in questo: la Risposta è notoriamente quarantadue, la Domanda non la sappiamo.
E in fin dei conti io non vedo nemmeno la spersonalizzazione della medicina paventata da Mezza. I famigerati R0 e Rt non sono per niente i sostituti dei medici. A parte che R0 è in realtà una chimera e nessuno sa davvero calcolarlo, anche perché per esempio la variante inglese ha con ogni probabilità fatto alzare quel valore, Rt è una specie di manopola per il “rubinetto contagio”. Più basso è il suo valore, minore è la probabilità di contagio e quindi la speranza di poterci finalmente liberare dalla pandemia: ma non è che un Rt basso dia un liberi tutti, come raccontava l’ex assessore Gallera. Quello a cui Rt serve è dare un aiuto ai medici, che quando trovano una persona con sintomi riconducibili al Covid sanno che l’infezione era già in atto da vari giorni ma non era semplicemente visibile.
In un mondo ideale… beh, un mondo ideale non avrebbe il Covid. Diciamo allora: in un mondo con risorse infinite potremo fare un tampone molecolare a tutti gli esseri umani una volta al giorno, e bloccare immediatamente un focolaio. A questo punto calcolare Rt non servirebbe a nulla. Ma il nostro pianeta ha risorse finite, e quindi dobbiamo lavorare con quello che c’è: appunto questo numeretto, o meglio il suo andamento nel tempo. Sì, proprio la “decifrazione per il trend dinamico” che a Mezza non piace: eppure è stata l’unica chance che avevamo. Possibilità giocata male, come abbiamo visto con l’arrivo della seconda e della terza ondata della pandemia; ma non si può dare colpa di questo alla matematica. Matematica che tra l’altro, come dicevo sopra, non intende ne può fare predizioni puntuali sul futuro: quello che può fare è fornire un ventaglio di possibilità, che poi dovranno essere comprese da chi deve decidere quali misure prendere, siano essi medici, politici o anche solo persone comuni.
Insomma la matematica e i matematici sono innocenti? Per la matematica direi sicuramente di sì: è un mezzo intrinsecamente neutrale. I matematici – e permettetemi di aggiungermi alla categoria – qualche colpa però ce l’hanno. Dovremmo essere capaci di spiegare molto meglio cosa stiamo dicendo e facendo quando sputiamo fuori numeri su numeri. Troppo spesso la matematica sembra magia, come dice la legge di Clarke per la tecnologia avanzata; ma la magia e le cose che non vengono spiegate possono essere accettate supinamente o rifiutate sdegnosamente, e con la matematica capita molto più spesso il secondo caso. Non è che può essere sempre colpa degli altri, no?


