DeepSeek ha imparato da ChatGPT?
OpenAI sospetta che i suoi servizi siano stati sfruttati senza autorizzazione per realizzare il nuovo discusso sistema di intelligenza artificiale cinese

OpenAI, la società statunitense che ha sviluppato ChatGPT, ha confermato di essere al lavoro per capire se la startup cinese DeepSeek abbia sfruttato alcuni dei suoi servizi per sviluppare il proprio sistema di intelligenza artificiale molto discusso in questi giorni. Se così fosse, OpenAI potrebbe richiedere che l’accesso a DeepSeek sia limitato per lo meno negli Stati Uniti, ma dimostrare lo sfruttamento dei suoi sistemi potrebbe rivelarsi difficile, sia da un punto di vista tecnico sia per la tutela del diritto d’autore.
In molti hanno inoltre osservato come OpenAI potrebbe trovarsi a dover difendere le sue proprietà intellettuali, in un periodo in cui sta affrontando numerose cause legali intentate dagli editori proprio per l’uso non autorizzato dei loro contenuti per sviluppare ChatGPT.
Nel caso degli editori, OpenAI è accusata di avere attinto agli archivi di giornali, gallerie fotografiche e piattaforme video per raccogliere grandi quantità di dati necessari per allenare i propri sistemi di intelligenza artificiale. OpenAI si difende dalle accuse sostenendo che i contenuti sono stati usati solo nella fase di sviluppo e che il sistema ne elabora di propri, gli editori sostengono invece che i loro contenuti siano spesso proposti tali e quali da ChatGPT, in violazione del diritto d’autore. Nel caso di DeepSeek le cose sono più complicate e legate a un particolare processo: la distillazione.
Come da un alcolico si ottiene un super alcolico tramite la distillazione, così nella “distillazione di conoscenza” si ottengono modelli di intelligenza artificiale più piccoli ed efficienti partendo da un modello più grande, che richiede invece maggiori risorse per essere gestito. In pratica si usa il miglior modello possibile a disposizione come insegnante per “formare” un modello più semplice, che impara da un sistema che ha già imparato a svolgere determinati compiti. Lo studente ha quindi una struttura semplificata e una quantità inferiore di parametri da utilizzare, cosa che permette di usarlo su computer meno potenti ottenendo comunque risultati validi.
L’insegnante viene utilizzato per produrre un insieme di dati e le relative previsioni. Quindi oltre a fornire le risposte corrette, fornisce anche le distribuzioni di probabilità associate a ciascuna possibile risposta (“soft target”). Detto in termini più semplici, il sistema non dà solo la risposta più probabile o quasi certa a una domanda, ma anche le altre che aveva valutato prima di rispondere. Se per esempio deve riconoscere l’immagine di una gallina, analizzandola assegna queste probabilità:
- gallina 65 per cento,
- gallo 30 per cento,
- piccione 5 per cento.
A una persona che utilizza il sistema serve solamente la prima risposta, mentre a un modello studente servono tutte e tre per valutare il grado di incertezza e confidenza nel processo di riconoscimento.
Utilizzando questi “soft target” lo studente non solo impara quale sia la risposta corretta, ma anche le relazioni e le somiglianze tra le diverse classi che hanno portato a quella risposta. In questo modo acquisisce la capacità di fare previsioni più accurate anche su dati che non aveva utilizzato durante la fase di addestramento. Si utilizzano inoltre sistemi per fare in modo che lo studente si avvicini sempre di più alle prestazioni dell’insegnante, pur mantenendo una struttura più semplice e di conseguenza una maggiore efficienza.
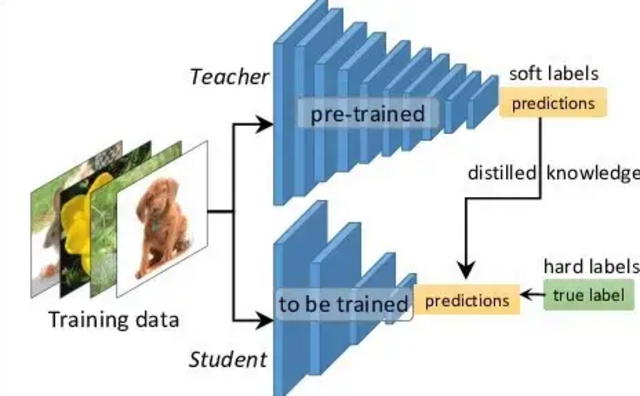
Rappresentazione schematica di un tipo di distillazione (Wikimedia)
La distillazione offre molti vantaggi, per esempio per realizzare modelli che possono effettuare dei compiti più semplici per i quali non è necessario avere a disposizione enormi capacità di calcolo. Per questo motivo tutti i principali sviluppatori di AI come OpenAI, Gemini e Meta derivano dai loro modelli principali dei modelli più piccoli. Per queste società è una pratica relativamente semplice da fare sui propri modelli, perché hanno pieno accesso alle loro funzionalità, ma può essere effettuata anche da soggetti esterni in modi più o meno creativi utilizzando sistemi che interrogano il modello.
Le società come OpenAI non permettono la distillazione dall’esterno e se notano qualcosa di strano possono provare a bloccare gli accessi a chi sta provando a farla, limitando per esempio la quantità di richieste che possono fare al sistema o specifici computer. In alcuni casi le attività di distillazione sono più sofisticate e passano inosservate, permettendo quindi a soggetti terzi di produrre proprio modelli sfruttando quelli di maggiore qualità che richiedono molte più risorse (in termini di capacità di calcolo dunque di denaro) per realizzarli.
La distillazione non autorizzata viene segnalata da tempo come un potenziale problema per la sostenibilità delle grandi aziende che sviluppano i modelli completi, come OpenAI e le altre. Queste società si fanno infatti carico di sviluppi che costano centinaia di milioni di dollari per produrre modelli di nuova generazione, sempre più potenti, mentre tutti gli altri sfruttano i loro investimenti per derivare modelli semplificati, più efficienti ed economici da far funzionare. Il settore è comunque ancora giovane e attraversato da fasi tumultuose, come quelle dell’ultima settimana, quindi è difficile stabilire se nel medio-lungo periodo sia più vantaggioso lo sviluppo dei modelli completi o di quelli distillati, soprattutto per alcune tipologie di operazioni.
Dall’analisi di alcune funzionalità di DeepSeek, OpenAI sospetta che l’azienda cinese abbia sfruttato parte delle proprie tecnologie per sviluppare un sistema di intelligenza artificiale che ha stupito molto, soprattutto per la sua capacità di funzionare con meno risorse rispetto alla concorrenza, pur dando risultati di alta qualità. Alcune fonti interne a OpenAI hanno detto al Financial Times di avere trovato alcuni indizi sulla distillazione, che violerebbe quindi i termini d’uso di ChatGPT.
La società per ora non ha però offerto altre spiegazioni e non è chiaro quali potrebbero essere le conseguenze nel caso in cui riuscisse a confermare la distillazione da parte di DeepSeek. Dopo il suo insediamento per il secondo mandato da presidente degli Stati Uniti, Donald Trump ha mostrato di avere un particolare interesse per i sistemi di intelligenza artificiale, ritenuti strategici per lo sviluppo tecnologico e industriale del paese. David Sacks, imprenditore scelto da Trump come consulente sulle AI, ha detto che ci sono «prove sostanziali» sull’estrazione di conoscenza da ChatGPT da parte di DeepSeek, ma non ha fornito dettagli.



{kind=link}