C’è un dibattito su un articolo scientifico con immagini senza senso
Con ratti superdotati e delle specie di ciambelle: è una cosa seria perché mette in discussione il processo di revisione e l'uso di software di intelligenza artificiale nella ricerca
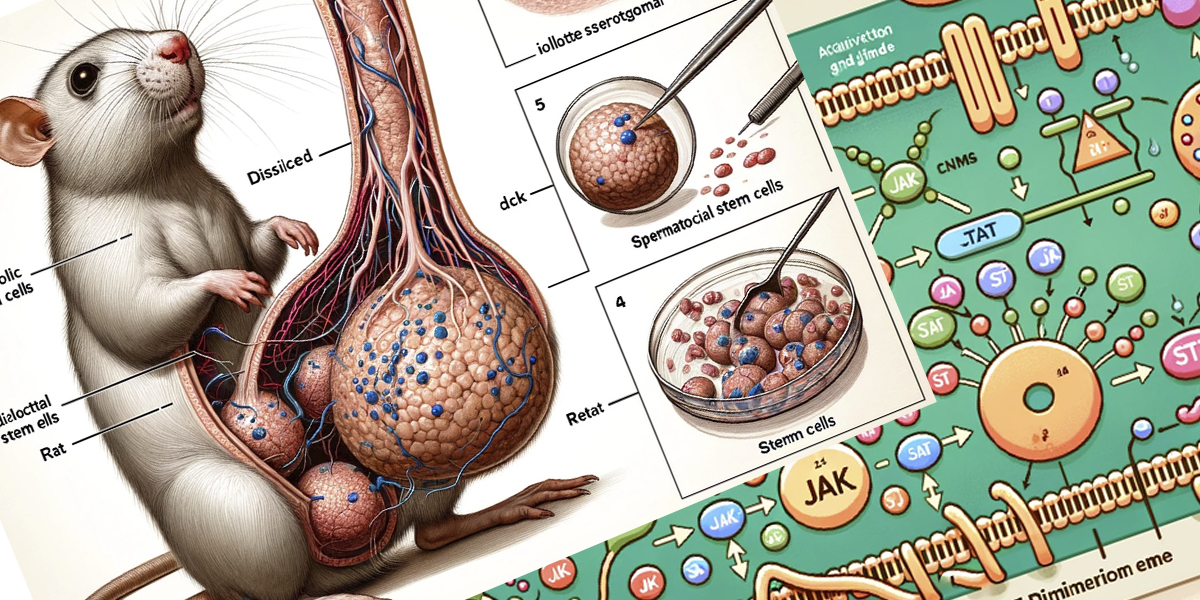
Il 16 febbraio la rivista scientifica Frontiers in Cell and Developmental Biology ha ritirato un articolo relativo a una ricerca sulle cellule staminali nei piccoli mammiferi pubblicato tre giorni prima, dopo che alcuni studiosi e ricercatori ne avevano scritto sui social facendo notare che le tre figure e le didascalie nell’articolo, create con un software di intelligenza artificiale, erano incomprensibili e assurde.
La vicenda ha generato una discussione sulla disattenzione dei revisori dell’articolo, da molti giudicata sconcertante vista la palese stranezza delle figure, tra cui il disegno di un ratto con un enorme organo genitale. La principale ragione per cui l’articolo ha ricevuto così tanta attenzione è che, come la maggior parte delle ricerche scientifiche, anche quelle pubblicate da Frontiers devono in teoria aver prima superato una revisione “tra pari” (peer-review), cioè da ricercatori terzi e indipendenti per verificarne l’attendibilità: cosa che in questo caso sembrerebbe non essere successa.
L’altra ragione per cui la disattenzione ha attirato un interesse molto ampio e diverse critiche alla rivista è che le immagini utilizzate come figure nell’articolo sono state generate tramite Midjourney, un popolare software di intelligenza artificiale. A dichiararlo apertamente a un certo punto nell’articolo erano peraltro gli autori stessi: tre ricercatori cinesi dell’ospedale Hong Hui e dell’università Jiaotong di Xian, nella provincia dello Shaanxi. Le norme redazionali di Frontiers non vietano di usare software come Midjourney, purché l’utilizzo sia dichiarato e i risultati siano comunque sottoposti a una verifica umana della loro accuratezza fattuale.
La rivista in questione fa capo all’influente gruppo editoriale Frontiers, e dopo che la polemica si è estesa su internet i redattori (cioè non quelli che hanno scritto l’articolo, ma quelli che ne hanno curato la pubblicazione) hanno solo fatto sapere che erano state sollevate «preoccupazioni riguardo alla natura dei dati generati dall’intelligenza artificiale» e di aver deciso di ritirarlo perché «non soddisfa gli standard di rigore editoriale e scientifico della rivista».
This one almost as good https://t.co/86SZUGXjJy pic.twitter.com/wAzVilorxv
— Craig Kaplan (@TriggerLoop) February 15, 2024
Molti commentatori appartenenti alla comunità scientifica si sono chiesti come le aberrazioni anatomiche e gli errori testuali nell’articolo siano stati ignorati o trascurati sia dagli autori che dal gruppo che ha approvato la pubblicazione. Si tratta peraltro di un tipo di errori bizzarri e abbastanza tipici degli attuali strumenti e software di intelligenza artificiale, quindi facilmente riconoscibili.
La prima figura mostra il disegno di un ratto su due zampe, con quattro testicoli e un pene molto più grande di lui, mostrati in sezione. Le parole utilizzate come didascalia – “iollotte sserotgomar cell”, “dck”, “testtomcels” – non hanno significato (ma per esempio “dck” sembra l’abbreviazione di “dick”, un modo colloquiale per dire pene in inglese). Così come non hanno significato anche quelle della seconda figura, che dovrebbe mostrare il percorso di un qualche segnale biochimico all’interno di una cellula ma sembra solo una spiegazione di «come fare una ciambella con dei confettini colorati», ha scritto la microbiologa olandese Elisabeth Bik, che si occupa di integrità della ricerca sul blog Science Integrity Digest. La terza figura dovrebbe infine mostrare delle rappresentazioni di come i segnali della seconda figura regolino le proprietà biologiche delle cellule staminali, ma sembrano «un mucchio di pizze con salame rosa e pomodori blu».
Analizzando qualche passaggio farraginoso nell’articolo, alcuni utenti hanno suggerito che anche il testo potesse essere stato generato utilizzando software di intelligenza artificiale. L’ipotesi è stata in parte avvalorata dai risultati di alcuni test eseguiti con appositi strumenti online, che tuttavia sono considerati inaffidabili a causa dell’alto numero di falsi positivi che restituiscono. Manuel Corpas, un professore di genomica e redattore per un’altra rivista di Frontiers, ha criticato duramente la ritrosia del gruppo a commentare la vicenda, chiarire i dubbi e condividere informazioni sulle varie fasi del processo di revisione.
Il ricercatore statunitense Jingbo Dai, biomedico della Northwestern University indicato come uno dei due revisori dell’articolo (l’altra è l’indiana Binsila B. Krishnan), ha spiegato a Vice di essere responsabile della revisione dell’articolo solo relativamente «ai suoi aspetti scientifici». Ha aggiunto che non era sua responsabilità esaminare le immagini, e che in merito all’accettazione dei dati generati dall’intelligenza artificiale la decisione finale spetta all’editore.
Adrian Liston, professore di patologia alla Cambridge University e caporedattore della rivista Immunology & Cell Biology, ha detto di aver lavorato in passato come redattore e revisore per Frontiers ma di aver smesso dopo essersi reso conto di quanto fosse difficile per il gruppo respingere un articolo. «Fondamentalmente è impossibile, puoi soltanto rimanere bloccato in cicli infiniti di revisione», ha detto Liston.
Attraverso il proprio account su X Frontiers ha ringraziato i lettori «per l’esame accurato degli articoli» e ha aggiunto: «quando sbagliamo, la dinamica di crowdsourcing della scienza aperta fa sì che il feedback della comunità ci aiuti a correggere rapidamente il documento».
– Leggi anche: Come capire le ricerche scientifiche
Diversi ricercatori ritengono significativa la “svista” di Frontiers giudicandola un effetto indiretto di una tendenza più ampia nel mondo accademico, già da tempo oggetto di un dibattito complesso sui limiti del sistema della revisione tra pari (che non sempre è una garanzia di qualità degli studi). L’idea sostenuta da diversi scienziati è che la ricerca sia sempre più influenzata da un sistema di incentivi economici che premiano autori ed editori per la quantità di pubblicazioni scientifiche, a scapito del rigore delle revisioni e della qualità degli studi.
Nello stesso dibattito circolano di conseguenza anche molte preoccupazioni riguardo al possibile impatto futuro dei software di intelligenza artificiale nella generazione di immagini e testi utilizzati negli articoli scientifici, soprattutto quelli di riviste affermate. Nel 2023, citando i rischi per l’integrità della ricerca, la rivista Nature introdusse nelle norme redazionali un divieto esplicito di utilizzo di software di intelligenza artificiale per creare immagini e video da inserire negli articoli.
Il processo di pubblicazione è sostenuto da un impegno condiviso verso l’integrità, che include la trasparenza, scrisse Nature. Ricercatori, redattori ed editori devono conoscere le fonti dei dati e delle immagini, in modo da poterne verificare l’accuratezza, e «gli strumenti di intelligenza artificiale generativa esistenti non forniscono l’accesso alle loro fonti in modo che tale verifica possa avvenire».
– Leggi anche: A chi appartengono le immagini generate dalle intelligenze artificiali?
In un articolo pubblicato a dicembre Nature descrisse il 2023 come di gran lunga l’anno con il maggior numero di articoli scientifici, oltre 10mila, ritirati dalle riviste che li avevano pubblicati. La maggior parte era stata ritirata non per errori in buona fede, ma per la presenza di dati inventati, figure e immagini già pubblicate in precedenza e testi generati tramite intelligenza artificiale. Il fenomeno aveva interessato prevalentemente Arabia Saudita, Pakistan, Russia, Cina ed Egitto, e in particolare le riviste dell’editore Hindawi, responsabile del ritiro di oltre 8mila articoli a seguito di indagini interne promosse dalla redazione dopo aver notato testi incoerenti e irrilevanti.
Nature scrisse che in generale il numero di articoli scientifici ritirati, circa 2 su mille, stava aumentando più rapidamente di quanto stesse aumentando il numero totale di pubblicazioni. E come ha detto la fisica e divulgatrice tedesca Sabine Hossenfelder è probabile che, man mano che gli strumenti di intelligenza artificiale diventeranno sempre più efficienti, individuare eventuali frodi scientifiche diventerà sempre più difficile, non più facile.
Frederik Joelving, redattore danese del blog Retraction Watch, che si occupa di ritrattazioni di articoli scientifici, ha recentemente scritto su Science di un aumento notevole di articoli ritirati dopo aver scoperto casi di corruzione, o altre manipolazioni del sistema della peer-review. In qualche caso, non limitato soltanto a editori poco famosi, i revisori fingevano di rivedere articoli generati tramite software di intelligenza artificiale. «Un portavoce di Elsevier [uno dei più grandi gruppi editoriali al mondo] ha detto che ogni settimana ai suoi editori vengono offerti soldi in cambio dell’accettazione degli articoli proposti», ha scritto Joelving, citando anche tentativi di corruzione rivolti a redattori di riviste del gruppo Taylor & Francis.
La vicenda dell’articolo ritirato da Frontiers, secondo Bik, una delle prime ricercatrici a renderla nota e approfondirla, è «un triste esempio di come riviste scientifiche, editori e revisori tra pari possano essere ingenui – o forse addirittura coinvolti nel giro – in termini di accettazione e pubblicazione di schifezze generate dall’intelligenza artificiale». Se illustrazioni così raffazzonate sono in grado di superare la revisione così facilmente, ha scritto Bik, «figure generate dall’intelligenza artificiale dall’aspetto più realistico probabilmente si sono già infiltrate nella letteratura scientifica».
– Leggi anche: Il caso che sta agitando le scienze comportamentali



