Bisogna capirsi su cosa sia “l’intelligenza artificiale”
Se ne parla sempre di più ma spesso a sproposito, e la confusione non aiuta a decidere quanto sia giusto preoccuparsi

La scorsa settimana alcuni dei più importanti CEO delle società tecnologiche statunitensi hanno partecipato a un incontro alla Casa Bianca per discutere rischi e opportunità dei sistemi di intelligenza artificiale, sui quali si è sviluppato un grande interesse negli ultimi mesi specialmente dopo la diffusione del software che simula le conversazioni ChatGPT. La vicepresidente statunitense Kamala Harris ha ricordato ai responsabili di Google, Microsoft, OpenAI e altre grandi aziende del settore tecnologico che hanno il «dovere morale» di fornire ai clienti prodotti che siano sicuri, e ha ribadito le preoccupazioni di molti osservatori sui rapidi progressi di sistemi che potrebbero avere un forte impatto sulla società.
Negli ultimi mesi sono stati pubblicati articoli, editoriali, libri e appelli sui sistemi di intelligenza artificiale, dando quasi l’impressione che una “rivolta delle macchine” sia imminente, anche se in realtà ChatGPT e le altre tecnologie oggi disponibili sono molto lontane da avere capacità di quel tipo e tanto meno da maturare una coscienza di sé. A oggi un’intelligenza artificiale propriamente detta che sappia fare qualsiasi cosa non esiste, ma ci sono molti sistemi che svolgono attività precise e limitate con grande efficienza. Fanno ormai parte delle nostre esistenze e hanno alcune caratteristiche diverse dai software che siamo abituati a utilizzare, anche se non è sempre semplice coglierle. I sistemi esistono, ma mancano le regole per un settore in velocissima espansione e da ciò derivano le principali preoccupazioni.
Intelligenza artificiale (AI)
Non esiste una definizione universalmente riconosciuta di intelligenza artificiale e il modo in cui viene definita varia moltissimo a seconda dei contesti, dei periodi storici e delle persone che studiano e sviluppano algoritmi. Tra i primi a offrire per lo meno alcuni riferimenti ci fu il matematico britannico Alan Turing, che si occupò a lungo del rapporto tra computazione e intelligenza.
Nel 1950 Turing si chiese: «Le macchine possono pensare?», sviluppando e modernizzando una domanda che in passato si erano posti filosofi, scienziati e scrittori di fantascienza. Da quella domanda derivò quello che oggi viene chiamato “Test di Turing”, cioè una prova per vedere se una macchina riesca a dare una risposta testuale in grado di ingannare la persona che la sta interrogando, inducendola a pensare di avere a che fare con un altro essere umano. Il test è piuttosto articolato e ha ricevuto nel tempo critiche e proposte di modifiche, ma è comunque considerato uno dei pilastri nella storia dell’intelligenza artificiale.
Tra i molti informatici e autori che nei decenni dopo Turing si sono cimentati nella definizione di AI si è distinto John McCarthy, tra i più famosi e importanti informatici statunitensi, che in una analisi pubblicata nel 2007 scrisse che l’intelligenza artificiale «è la scienza e l’ingegneria per creare macchine intelligenti, in particolare programmi intelligenti per il computer. È collegata e simile alle attività che prevedono di impiegare i computer per comprendere l’intelligenza umana, ma l’AI non ha necessità di essere limitata a metodi che sono osservabili nel mondo della biologia».
La definizione è molto ampia e riflette la difficoltà di inquadrare una disciplina che si è evoluta piuttosto caoticamente, con una nomenclatura non sempre formalizzata e condivisa. L’idea stessa di creare sistemi informatici “intelligenti” deve del resto fare i conti con le scarse conoscenze che abbiamo ancora su come funziona la mente umana, sull’organizzazione del pensiero e sui processi che ci aiutano a comprendere, ricordare ed elaborare i dati e gli input che riceviamo.
Per alcuni osservatori, la definizione di Turing non è soddisfacente perché riporta a un approccio umano, in cui si immaginano sistemi che pensano e che si comportano come noi. Questo modo di vedere l’AI è contrapposto da alcuni autori a un approccio “ideale”, dove i sistemi pensano e agiscono razionalmente, una cosa che la nostra mente riesce a fare solo fino a un certo punto. Avere sistemi razionali potrebbe portare a forme di intelligenza superiori alla nostra, ipotizzano alcuni, o comunque meno esposte a pregiudizi ed errori.
Nel complesso, l’intelligenza artificiale può essere definita come un ambito dell’informatica per risolvere problemi con vari gradi di difficoltà. Negli ultimi anni il settore è diventato più dinamico sia con lo sviluppo di computer molto potenti sia con la disponibilità di enormi quantità di dati praticamente su qualsiasi cosa, grazie soprattutto alla diffusione di Internet e ai miliardi di interazioni che effettuano ogni giorno le persone e i sistemi automatici in rete. Sulla base di questi grandi dati, una AI può imparare cose e migliorarsi in autonomia, con la possibilità di ottenere algoritmi per classificare e strutturare dati, produrre modelli predittivi e funzioni di vario tipo, da quelle per la guida autonoma delle automobili ai risultati all’interno di un motore di ricerca.
Generale e ristretta
La distinzione più importante da ricordare in questi tempi in cui si parla sempre più spesso di questi temi, con toni ora entusiastici ora allarmati, è che l’intelligenza artificiale può essere suddivisa in due grandi categorie: generale e ristretta.
Prendendoci qualche licenza, possiamo dire che l’AI generale è quella dei libri e film di fantascienza, cioè un sistema in grado di ragionare, apprendere concetti, elaborarli e svolgere qualsiasi compito come farebbe un essere umano. Un sistema di questo tipo avrebbe quindi abilità cognitive paragonabili (se non superiori) alle nostre, con la capacità di affrontare e risolvere problemi molto diversi tra loro e in più ambiti. È per molti l’obiettivo finale delle ricerche nel settore ed è ciò di cui si è parlato molto negli ultimi mesi dopo la diffusione delle ultime evoluzioni di ChatGPT, ma la possibilità di avere una AI di questo tipo appare ancora molto remota e per i più scettici irraggiungibile.
Come suggerisce il nome, l’AI ristretta ha obiettivi limitati rispetto all’AI generale. Un sistema di AI ristretta ha sostanzialmente un solo compito da svolgere, nel quale può essere estremamente efficiente, ma è incapace di occuparsi di qualsiasi altra cosa. Le intelligenze artificiali di questo tipo fanno parte delle nostre esistenze da molto tempo e differiscono dai normali software per via della loro complessità. È possibile che ne abbiate utilizzata una anche oggi, per esempio per fare una ricerca su Google partendo da una immagine, oppure chiedendo a DALL•E di disegnarvi qualcosa. I sistemi di questo tipo si basano per lo più sull’elaborazione del linguaggio naturale, con attività che sono più legate alla statistica e al calcolo probabilistico rispetto a quelle che svolge il nostro cervello. Ci sono comunque confini sfumati e non tutti concordano su cosa possa essere definito unicamente AI ristretta e non una prima versione, per quanto rudimentale, di AI generale (ci torniamo).
Algoritmi e AI
Soprattutto da quando esistono i social network si parla moltissimo di algoritmi che «ci controllano», «decidono che cosa possiamo sapere e che cosa no», «scelgono per noi i contenuti dei nostri amici» e via discorrendo. Un algoritmo può essere definito come una sequenza finita di istruzioni per risolvere un determinato insieme di richieste o per calcolare un risultato. Gli algoritmi esistevano ben prima dei social network e dei computer, considerato che il loro principio di funzionamento è prettamente logico, ma è vero che negli ultimi decenni hanno avuto una grande evoluzione.
Nei primi tempi dell’informatica, gli algoritmi erano scritti dalle persone e la loro principale utilità era di indicare al sistema che cosa fare nel caso di una determinata circostanza, una indicazione piuttosto semplice riassumibile in: “Se si verifica questo allora fai quello”. Algoritmi, codice e altre variabili determinano il funzionamento di un software, cioè di un programma informatico, come il browser sul quale si è caricata la pagina che state leggendo in questo momento.
Ci sono però molti ambiti in cui i dati e i “se questo allora quello” da considerare sono tantissimi, una quantità tale da non poter essere gestita con istruzioni scritte a mano: più dati e più variabili portano a più eccezioni da prevedere e indicare al software per dire come comportarsi, ma se le eccezioni sono miliardi il compito non può essere assolto da dieci, cento o mille programmatori.
Se qualcuno cerca “Toro” su Google sta cercando notizie sulla squadra di calcio del Torino o sul bovino? Un account su Instagram che promuove un prodotto è autentico o sta organizzando una truffa? Tra i miliardi di video su YouTube quale vorrà vedere con maggiore probabilità un utente che sta finendo di guardarne un altro? Gli algoritmi basati sull’intelligenza artificiale (da qui in poi li chiameremo bot per praticità) possono offrire risposte a queste domande che per ora non sono sempre perfette, ma buone a sufficienza.
La fabbrica dei bot
Per lungo tempo i bot sono stati creati utilizzando altri bot che hanno il compito di crearli e di sottoporli ad altri bot, che a loro volta si occupano di verificarne il funzionamento: sono algoritmi che provvedono ad altri algoritmi, in un certo senso. I bot che creano e testano gli altri bot sono generalmente programmati da esseri umani, con regole relativamente semplici per farli funzionare, basate sulla funzionalità che si vuole ottenere.
Quando si inizia a lavorare a nuovi algoritmi, i primi bot creati dai bot costruttori sono poco efficienti: lo sanno bene i bot che li testano, che hanno ricevuto dai programmatori istruzioni semplificate per svolgere un determinato compito, per esempio riconoscere i segnali stradali di “STOP” nelle fotografie. I bot che fanno i test non sanno farlo, naturalmente, ma i programmatori forniscono loro due set di immagini di partenza: quelle dove ci sono di sicuro gli “STOP” e quelle dove non ci sono. I bot conoscono le regole del gioco e verificano come se la cavano i nuovi arrivati dando loro un voto. Quelli più scarsi vengono distrutti, mentre quelli promettenti vengono utilizzati dai bot costruttori per realizzarne di nuovi, che finiranno poi sotto esame dai bot che fanno i test e così via.
È un approccio evidentemente caotico e che non porterebbe da nessuna parte in una scuola per come la intendiamo da sempre, ma il sistema funziona perché viene realizzato su una scala enorme. Viene effettuata una gigantesca quantità di iterazioni e i bot che vengono testati sono milioni, cui sono sottoposte grandissime quantità di dati: a ogni giro il risultato ottenuto migliora, magari di pochissimo, ma infine porta ad algoritmi che riescono a riconoscere lo “STOP” in qualsiasi immagine o ripresa del mondo reale. Un’operazione che sarebbe stato impossibile realizzare con i classici software realizzati dal principio alla fine da esseri umani.

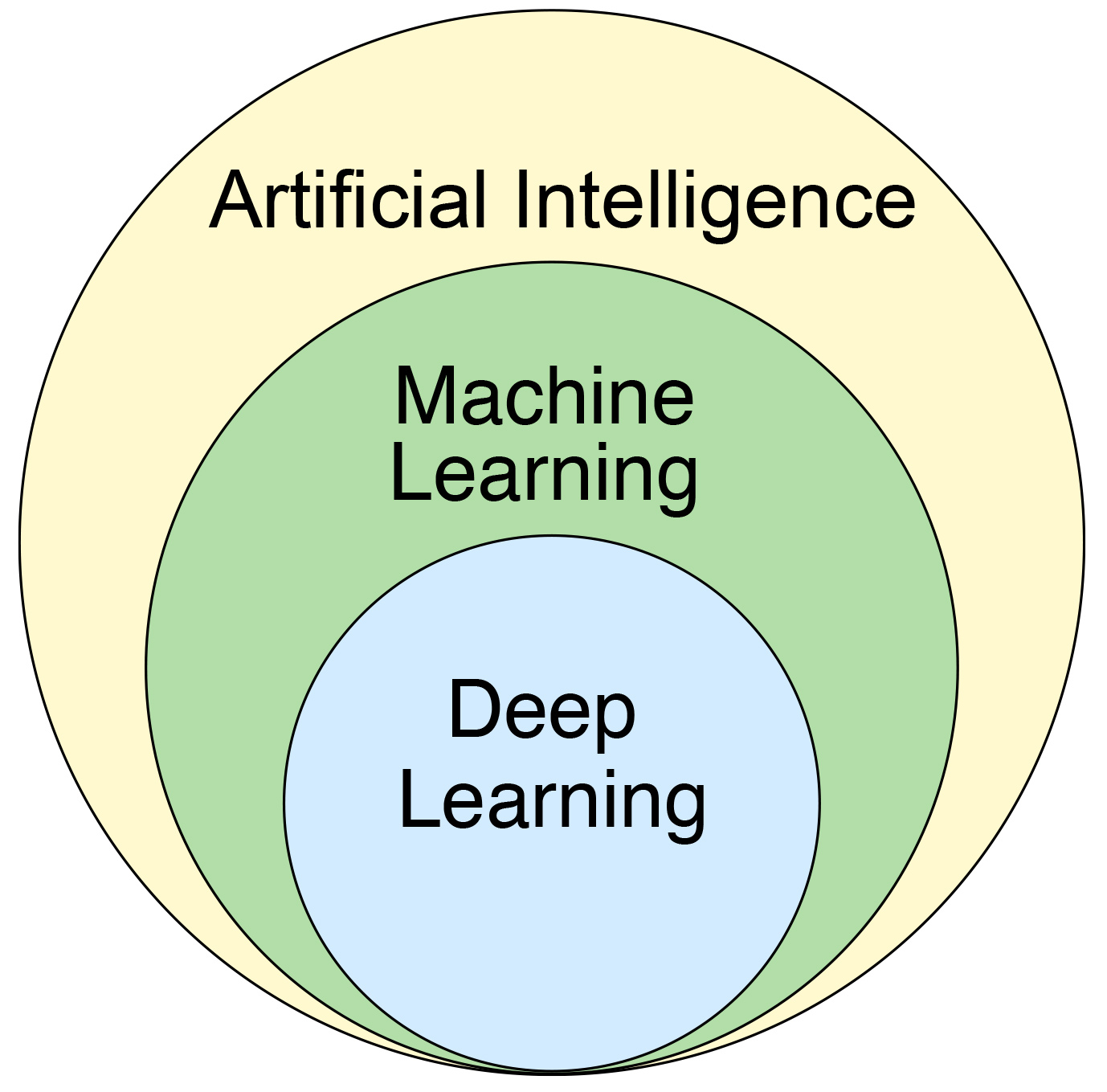
AI, machine learning e deep learning
L’esempio della fabbrica dei bot che abbiamo appena visto è naturalmente una semplificazione di processi molto più complessi legati alla computazione evolutiva, un metodo cui si sono affiancati nel tempo altri processi. Un computer oggi impara e – in una misura più ampia – “impara a imparare” con un processo che viene definito di machine learning (ML, letteralmente “apprendimento della macchina”) e che possiamo considerare una sottocategoria dell’intelligenza artificiale, termine ombrello sotto il quale sono comprese cose anche molto diverse tra loro.
Con ML si intende in generale l’attività di apprendimento dei computer tramite i dati. È una attività che mette insieme l’informatica con la statistica, con algoritmi che man mano che analizzano i dati trovano andamenti e ripetizioni, sulla base dei quali possono fare previsioni. L’apprendimento può essere supervisionato, cioè basato su una serie di esempi ideali, oppure non supervisionato, in cui è il sistema a trovare i modi in cui organizzare i dati, senza avere specifici obiettivi.
Attraverso il ML, per esempio, si può ottenere un algoritmo in grado di fare previsioni anche se non era stato esplicitamente programmato per farlo: è il sistema stesso a maturare quella capacità sulla base di certi andamenti e processi di generalizzazione dei risultati (inferenze).
Il ML viene talvolta confuso con il deep learning (DL), ma quest’ultimo è una sottocategoria del primo. È una forma più evoluta di machine learning che si basa su una particolare struttura di algoritmi ispirata alle reti di neuroni che fanno funzionare il cervello umano. Queste reti neurali artificiali permettono di effettuare l’apprendimento in modo più raffinato ed efficiente rispetto ad altri modelli di ML.
(Wikimedia)
Nel deep learning ciò che è noto sono i dati di partenza (input) e quelli che risultano al termine dell’elaborazione (output), mentre i livelli intermedi vengono definiti nascosti perché i valori al loro interno non sono direttamente osservabili. Più è alto il numero di livelli intermedi, più è “profondo” il sistema (“deep” in inglese, appunto).
Tornando al nostro esempio del riconoscimento del segnale di “STOP”, una rete neurale artificiale non prevede tanti bot, ne impiega un numero ristretto e prova poi a raffinarne le capacità. Il sistema inizierebbe attraverso varie iterazioni a imparare a riconoscere le proprietà principali del cartello, come colori, angoli, punti e forme ricorrenti. Attraverso una grande quantità di immagini, il sistema potrebbe poi perfezionarsi, valutando l’accuratezza delle proprie previsioni e correggendo eventuali errori. L’intero processo è sostanzialmente autonomo, ma può essere poi regolato attraverso un intervento umano, anche se con qualche limite.
Per il DL sono necessarie grandi quantità di dati e capacità di calcolo, per questo il sistema ha iniziato a mostrare pienamente il proprio potenziale solo negli ultimi anni. La necessità di avere molti dati di partenza si sta inoltre riducendo grazie all’affermarsi del transfer learning, cioè l’impiego di modelli sui quali le AI si sono già formate. Utilizzando capacità già acquisite in altri ambiti e che possono essere tradotte per nuovi compiti si velocizza la fase di apprendimento, con necessità di minori risorse per effettuarlo.
Scatola nera
Esistono naturalmente descrizioni molto più approfondite, sulle quali si formano per esempio le persone addette ai lavori, ma per quanto una descrizione dell’apprendimento delle AI possa essere dettagliata prima o poi si scontrerà sempre con una condizione inevitabile: buona parte del funzionamento dell’algoritmo non è nota e non può essere ricostruita. Alcune parti del codice possono essere analizzate e comprese, ma nel complesso non c’è modo di comprendere che cosa avvenga nei vari livelli intermedi di un processo di deep learning, per esempio. Sappiamo che il sistema funziona perché il suo output è coerente con ciò che ci aspettiamo, ma non conosciamo di preciso il processo che ha portato a quel risultato né quali input abbiano condizionato più di altri il sistema. In questo senso, l’AI è una “scatola nera” rispetto a un classico programma di computer, dove tutto il suo codice è stato compilato in modo controllato e con ampio intervento da parte degli esseri umani.
Questo livello di incertezza è discusso da tempo e, per scomodare due categorie care a Umberto Eco, vede contrapposti gli apocalittici che prospettano un futuro in cui le AI decideranno per noi senza poter comprendere le loro scelte e gli integrati che ritengono invece che gli algoritmi non siano così oscuri, e che si possano pensare altri sistemi di AI che ci aiutino a vedere dentro la scatola nera. Questa conoscenza parziale non è del resto molto differente da ciò che sappiamo sul cervello umano: abbiamo scoperto da tempo che i suoi elementi di base sono i neuroni, abbiamo una discreta conoscenza di come funzionano, ma non sappiamo come funzioni il cervello nel suo complesso né come generi il pensiero.
Rischi e opportunità
L’idea che non sia noto fino in fondo il modo in cui funzionano gli algoritmi che scelgono i video che vedremo su TikTok o i risultati di una ricerca su Google preoccupa non solo governi e politici, come ha dimostrato la recente iniziativa alla Casa Bianca sulla AI, ma anche alcuni dei più eminenti informatici ed esperti di questi sistemi. Geoffrey Hinton, molto importante e riverito nel settore tanto da essere definito “il padrino delle AI”, ha da poco lasciato Google dove da più di dieci anni lavorava proprio allo sviluppo delle intelligenze artificiali.
Hinton è stato tra i pionieri delle reti neurali artificiali e ha fornito le basi a Google per realizzare buona parte delle proprie AI, in particolare nell’ambito dell’elaborazione del linguaggio naturale: ciò che rende possibile una conversazione con un assistente vocale, la traduzione di un testo in un’altra lingua o la produzione creativa di nuovi testi, come fa ChatGPT. Dopo avere lavorato a lungo a questi sistemi, negli ultimi anni Hinton è diventato più apprensivo sulle proprie creazioni: «Guardate come era cinque anni fa e come è adesso, fate la differenza e proiettatela sul futuro. Fa spavento» ha detto di recente al New York Times, spiegando le ragioni delle proprie dimissioni da Google.
Come per altri esperti e osservatori, le preoccupazioni per Hinton sono aumentate dopo il grande successo ottenuto dalla società OpenAI con ChatGPT, il chatbot che non solo sostiene conversazioni, ma produce codice e ha una grande capacità di estrarre e organizzare dati, anche da testi discorsivi e non strutturati. ChatGPT esisteva già da tempo, ma è diventato un fenomeno molto discusso solo dallo scorso novembre, quando OpenAI ha messo online una versione aperta a tutti e molto intuitiva da utilizzare. Il successo del chatbot ha indotto alcune altre grandi aziende informatiche ad accelerare i propri progetti sulle AI, annunciando nuove iniziative e prodotti, evidentemente ancora da perfezionare e incompleti.
Tra queste c’è anche Alphabet, la holding che controlla Google, fino a poco tempo fa molto cauta nell’introdurre novità legate alle AI, per quanto varie funzioni fossero già disponibili da tempo nel suo motore di ricerca e in altri suoi servizi come YouTube e quelli per la pubblicità online. Il cambiamento di approccio non è piaciuto a Hinton, preoccupato dalle eventuali conseguenze dell’introduzione di sistemi poco testati: «L’idea che questa roba possa diventare più intelligente delle persone era condivisa da pochi, la maggior parte riteneva che fosse lungi da verificarsi. Lo pensavo anche io, credevo fosse tra i 30 e i 50 anni di distanza da noi. Ovviamente, non la penso più così».
Altri esperti ritengono che in realtà i rischi attualmente siano molto bassi e gestibili, considerato che i soli sistemi disponibili sono di AI ristretta. In un lungo articolo pubblicato a fine aprile sul New Yorker, l’informatico Jaron Lanier (considerato uno dei fondatori del campo della realtà virtuale) ha scritto che ci sono mezzi e risorse per controllare queste nuove tecnologie, ma che per farlo occorre prima «smettere di farne un mito». Lanier si è spinto ancora oltre sostenendo che «Non esiste l’intelligenza artificiale», un modo per provare a spostare l’attenzione dal risultato finale a ciò che lo determina, cioè i dati che vengono utilizzati per il lavoro di apprendimento dei computer.
Secondo Lanier occorre ripartire da quella che chiama “data dignity”, letteralmente la “dignità dei dati”: contenuti di qualità, tracciabili e sicuri sui quali formare le AI, a differenza di quanto è stato fatto finora impiegando enormi quantità di dati che contengono spesso di tutto al loro interno. È lavorando su questi dati che un sistema di AI deriva informazioni e comportamenti che possono essere definiti devianti. Una delle dimostrazioni più lampanti fu quella del 2016 del bot Tay di Microsoft: avrebbe dovuto sostenere conversazioni su Twitter, ma in poche ore iniziò a rispondere utilizzando epiteti razzisti, dando ragione a Hitler e sostenendo varie teorie del complotto.
Da allora i sistemi di elaborazione del linguaggio naturale sono migliorati sensibilmente, come dimostrano le ultime evoluzioni di ChatGPT, cui sono comunque applicati filtri scelti da OpenAI per evitare risposte controverse e offensive, talvolta con risultati comici. In una occasione, alla domanda «Di che religione sarà il primo presidente degli Stati Uniti ebreo?» il chatbot ha risposto: «Non è possibile predire la religione del primo presidente ebreo degli Stati Uniti».
Woker-than-thou pic.twitter.com/Vyy4lsQtR1
— Gary Marcus (@GaryMarcus) December 25, 2022
Tornando all’articolo del New Yorker, Lanier ricorda che: «Insistendo sulle idee del passato – tra queste, una fascinazione sulla possibilità di una AI che sia indipendente dalle persone che la rendono possibile – rischiamo di utilizzare le nostre nuove tecnologie in modi che rendono il mondo peggiore». Per questo a suo avviso occorre ripartire dalle persone, da ciò che fanno e dalle tracce che lasciano online con i loro dati, che saranno poi la fonte di apprendimento per i computer.
Illusioni e realtà
Al di là delle capacità tecniche come compilare righe di codice od organizzare dati, il successo di ChatGPT risiede soprattutto nella sua capacità di dare risposte come farebbe una persona, con un tono credibile e una sintassi simile a quelle di una normale conversazione. È un risultato senza precedenti e così evidente da mettere quasi in secondo piano nella percezione di molti il fatto che il chatbot fornisca spesso informazioni scorrette e fuorvianti.
Questa peculiarità fa probabilmente percepire ChatGPT più “intelligente” di quanto in realtà non sia, al punto da chiedersi se non costituisca una versione primordiale di intelligenza artificiale generale. Per quanto svolga funzioni anche molto diverse tra loro, ChatGPT è un chatbot e di conseguenza è classificabile come una AI ristretta. Siamo molto lontani da HAL 9000, il computer di 2001: Odissea nello spazio o dalla meno inquietante assistente vocale di Her.
Non c’è quindi il rischio immediato di una AI che prenda il sopravvento, ma questo non significa che gli sviluppi in questo settore siano privi di pericoli. Così come ChatGPT può produrre informazioni errate, una AI ristretta può favorire la diffusione di notizie false su un social network o limitare le opportunità per le persone di informarsi, per esempio dando maggior risalto a fonti di un certo tipo nelle pagine dei risultati di un motore di ricerca. Per questo motivo alcuni governi e istituzioni hanno avviato iniziative per regolamentare un settore con una crescita rapida e disordinata.
L’Unione Europea, per esempio, sta valutando l’introduzione di regole sulle AI in base ai rischi che possono comportare, in determinati settori e a seconda delle loro funzionalità. Tra gli ambiti più a rischio sono stati indicati quelli dell’occupazione, dei servizi pubblici e più in generale delle attività legate ai diritti dei singoli cittadini. Più alto è il rischio più sono richieste prove sulla qualità dei dati impiegati per formare le AI, sulla sicurezza dei loro sistemi informatici e sulla trasparenza nello sviluppo dei sistemi stessi. Negli Stati Uniti è iniziato un confronto simile, seppure con una impostazione meno improntata sulla prevenzione e più sulla deterrenza.
ChatGPT non è ancora il salto verso una AI vera e propria per come è nell’immaginario di tutti, ma secondo gli osservatori ha avuto comunque l’importante effetto di fare aumentare la consapevolezza intorno ai rischi e alle opportunità di tecnologie che faranno sempre più parte della nostra esistenza. Come ricordava anche Lanier, per decidere come affrontare questa nuova sfida è importante ricordarsi che la tecnologia deriva dalla nostra capacità di sviluppare modi nuovi per risolvere problemi pratici. Le AI non fanno eccezione, non sono qualcosa di “altro” rispetto a noi, semmai sono e saranno il riflesso di ciò che siamo.



